Note: cloud environment is charging by second / hour


When exploring the relevant AWS services, if one wants to employ an IT architecture that is fit for purpose and fit for use, inevitably a solution architect tries different alternatives until the final solution architecture is found for the given business goal.
For example, when dimensioning the resources needed to support the business flow, as far as computers are concerned (in fact servers), there are several alternatives to pick from as follows (the below list is not exhaustive):
- EC2 on-demand instances
- EC2 reserved instances
- EC2 spot instances
Note: EC2 instance = a virtual machine a.k.a a virtual server (there is a discussion here though, as the term ‘server’ could be also a piece of software as opposite to the ‘classic’ meaning of server that commonly is seen as a computer / a physical piece of hardware on a rack of servers/machines).
Each one of the above types of instances qualifies for various purposes.
For example, on-demand EC2 instances are needed for a critical situation whereby availability of the business process is critical (for example a database replication). Spot EC2 instances could be used for say processing images whereby interruption is not important (you can re-take the processing of that image at a later stage without much impact on the underlying business process).
Interruption? Yes, spot instances could dissapear (automatically terminated / stopped by Amazon when the price increases unexpectedly).
Why one might chose a spot EC2 instance if it could have an impact on availability? The major difference between EC2 on-demand and spot EC2 is the pricing (the IT architect may chose one in order to make significants savings, provided that the nature of business allows to include in the landscape such a thing).
The process when chosing an EC2 spot instance is this: you know from the start that spot instances could not be available by reasons independent of your will. Still, you want to take the risk to employ such an instance because the price is … way too low (6-8 times than the EC2 reserved instances). So, at the beginning you bid a price for a spot EC2 instance and you are aware that when that price cannot cover the market price, Amazon gets that EC2 instance away from you (it leaves you however 2 – yes, two – minutes to react).
Ok, so no matter the type of instances picked, the IT architect is reponsible to chose an architecture able to accommodate the nature and complexity of company’s business at best prices offered by the cloud.
Finally, after one or many drafts of IT architecture, the architect decides on a pool of EC2 instances. Once the final IT architecture is ready, if he/she overlooks an EC2 instance that is not included therein, that forgotten one might continue to be seen by Amazon as a resource needed (as long as it is not terminated) and therefore charges will be incurred for this instance.
That is why it is highy recommended to use a method to keep the costs under control and one of the recommended ways to achieve this objective could be by implementing … alerts.
Note: Why an IT architect might overlook to terminate an EC2 instance ? It may happen he/she might have a good intention, meaning after many tries, such instance might have on it valuable data. So, before to terminate that instance the intention was to 1) copy first the data and 2) then cancel that instance. But maybe between step 1 and 2 something happened and that EC2 instance remains unterminated.
Anyway, alerts are a good thing.
Feature in AWS: creating a budget thresold comes with the nice option of setting an alert when budget is exceeded.

How to set up a buget thresold in order to keep costs under control?

The answer is there is the option to set budget(s) – see in the above image the button “Create budget”. This option comes with the feature to send an email when the budget is exceeded.
I like especially this couple of possibilities, as follows:
- the alert could be set at a threshold that represents x% of the budget;
- alerts could be set for both actual budget and forecasted* budget (or for only one of them).
*) Amazon makes a forecast based on the past levels of costs (registered in consuming of resources)
Why alerts are so important?
To answer this question, I believe first we have to find the answer to another question, i.e. what could go wrong?
Let’s explore another example besides the one already mentioned (i.e. I have talked several paragraphs above about the possibility to overlook to terminate or – at least – to stop an unused instance).
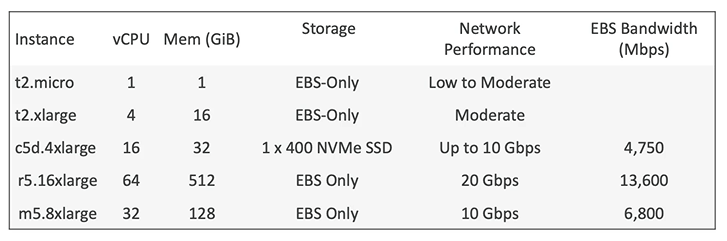
Among other decisions that have to be made, the IT architect has to take into consideration the type of instance to serve best the nature of business. Here below there is a list of the instance types available in AWS (categorized by the main purpose they serve):

Those various types of instances (i.e. virtual servers) are meant to optimise different components of a server room. As such, among other things that qualifies as targets for optimisation – the most important computer resources are:
1) memory (when it is required fast performance, i.e. for workloads that process large datasets in memory such as in-memory databases optimised for Business Intelligence activities, or applications performing real-time processing for big unstructured data);
2) storage (for storage-intensive tasks that require high, sequential read and write access to large data-sets on local storage – examples: data warehousing applications or high frequency online transactions processing systems);
3) computer processing power (for compute-intensive tasks, such as games or in scientific modelling & machine learning or for media transcoding). For the later purpose (computer processing power) Amazon offers a “Compute optimised” type of instance.
I think you got the picture. Here below there are details about various EC2 instances available:
Still, I did not answer yet the question “What could go wrong?” but wait, soon this will be revealed.
The company has a CIO (Chief Information Officer) or CTO (Chief Technology Officer) or similar being in charge with IT function. If this person is confident from the beginning and he/she assesses the volume of business (based on company’s requirements) as significant – let’s suppose a business of a company at the beginning of its operations, then the architect can pick a c5d4xlarge instance (from the table above).
However, if volume of business was overestimated, then the IT architect might be required by life to accommodate this change. Therefore, he/she might decide to chose a new instance, i.e. one that has a lower capacity (say t2xlarge with only 4 virtual CPU – Central Processing Units instead of 32 virtual CPUs).
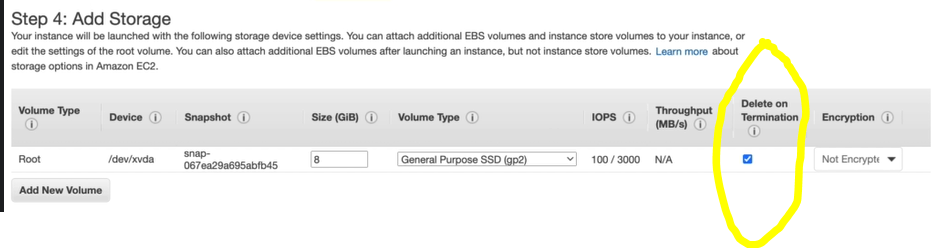
Consequently, the architect will of course terminate the initial instance (i.e. c5d4xlarge), but when that initial instance was created – if the button “Delete on Termination” (see image below) was not ticked, and the architect will not check specifically to delete / terminate also the storage, then we have a problem: the old instance is terminated but not the storage. The later might continue to consume resources.
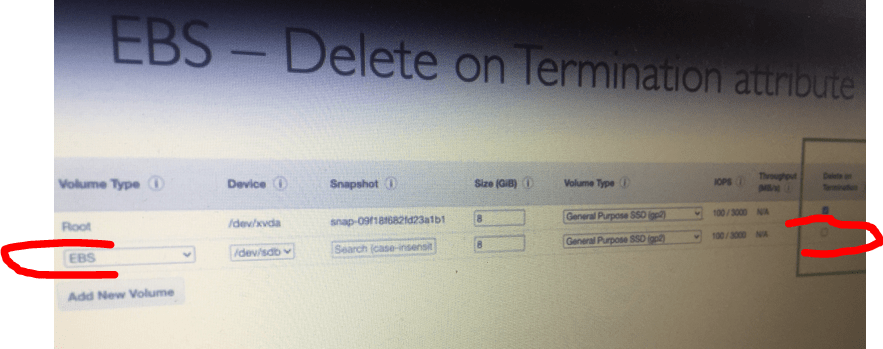
Or, it may happen that the respective EC2 instance, even though the button “Delete on Termination” was ticked, an additional EBS volume had been attached previously – as a secondary drive (EBS stands for Elastic Block Storage). This EBS volume will not be destroyed when the instance was terminated, so it will keep the data (and consume resources).
Not to mention there is also the option to employ an EC2 hibernate instance. There is a slight chance that such an instace to be also overlooked by the IT architect (if a bad luck, although initially the architeht having good intentions – i.e. to not delete valuable data) and therefore they will continue consuming resources without the company being aware that such an instance is alive (despite the fact that it is not included in the final architecture).
So, as a conclusion a couple of things could go wrong.
Hence the need to control when a budget (or a fraction of it – for example 10% or 20%) is exceeded. If it happens that the respective thresold is exceeded earlier than expected, an automatic email / alert would be an early warning sign and this is exactly what a financial manager of that company needs.
He/she is thus able to ask people in charge why such increase in costs and this is a good start in remediation. Actions to repair what went wrong will be triggered as a result.
It is best to know this before end of month because at the end of month it’s already too late (the bill could be fat and nothing could be done at that stage).
